
SHA-1, short for Secure Hash Algorithm 1, is a cryptographic hash function that has been an integral part of the digital landscape for several decades. Though it has undergone scrutiny and demonstrated weaknesses over time, its operational mechanisms remain a cornerstone of understanding cryptographic principles. To appreciate SHA-1’s myriad functionalities, one must delve into its construction, computational pathways, and implications for security.
At its core, SHA-1 is designed to accept an arbitrary-length input and produce a fixed-length output of 160 bits. This characteristic confers a key benefit: irrespective of the size of the data it processes, the output remains constant. Such consistency fosters manageable verification and facilitates data integrity checks. However, this uniformity is merely the tip of the iceberg; the underlying processes reveal a fascinating tapestry of mathematical elegance and computational ingenuity.
The journey of data through SHA-1 begins with preprocessing. This phase entails padding the input message to ensure its length is congruent with the algorithm’s requirements. Padding is vital, as it aligns the message length to a multiple of 512 bits. The final 64 bits of the padded message encapsulate the original length of the unaltered message. This preemptive step guarantees that the hash function can conduct a proper analysis, minimizing the risk of errors in subsequent operations.
Following the preprocessing stage, the algorithm enters the intricate realm of message parsing. Here, the input is segmented into blocks of 512 bits each. Following segmentation, each block is further subdivided into 16 words of 32 bits. The ingenious aspect of SHA-1 unfolds as it employs a linear transformation utilizing these words. The mechanism extracts data dependencies through a series of mathematical operations, ultimately leading to a discernible hash value.
The real marvel lies in the iterative process that takes place in the compression function. Each of the 80 iterations (the heart of SHA-1) utilizes a mix of logical operations, additions, and constants. During these iterations, the function applies bitwise manipulations, utilizing the fundamental operations of AND, OR, and NOT. Each iteration combines the output of the previous step with specific constants derived from the sine function, imbuing the process with an unpredictable flavor. This seemingly whimsical approach belies a complex interdependence among bits that enhances security and resilience.
One cannot overlook the role of initial hash values in this digest process. SHA-1 employs five specific constantes to initiate the hashing process, referred to as the initial hash values. These fixed values anchor the entire hashing operation, providing a foundational structure that the ensuing operations build upon. Over subsequent iterations, the values are manipulated through a series of additions, compounded by rotations and shifts, leading to a concoction of hash values that manifest in the final digest.
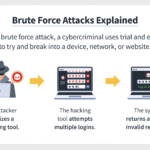
Yet, as the digital landscape has evolved, so too have the cryptographic standards by which it is governed. While SHA-1 was once heralded as a stalwart defender against vulnerabilities, advancements in computational power and cryptanalysis techniques have revealed its limitations. The discovery of practical collision vulnerabilities has sparked significant debate and concern within the cryptographic community. A collision occurs when two different inputs yield the same hash output, undermining the entire premise of data integrity.
Curiosity piques at the thought of how these collisions manifest. Researchers utilize careful techniques, including differential cryptanalysis, to uncover potential weaknesses. This method involves assessing how slight variations in the input can cause deviations in the output, enabling the discovery of collisions faster than would conventionally be expected. Armed with this knowledge, attackers may craft malicious inputs to generate matching hashes, thereby compromising system integrity without detection.
Despite these concerns, understanding SHA-1’s operational mechanisms enhances our overarching comprehension of cryptographic hash functions. It forms a basis from which one can explore the more contemporary alternatives that have arisen in response to SHA-1’s drawbacks. Functions like SHA-256 and SHA-3 provide increased security standards by utilizing longer hash outputs and more intricate algorithms, reflecting a robust trend in cryptography towards resilience in the face of evolving threats.
Moreover, it is crucial to spotlight the practical applications of SHA-1 that have persisted, even in light of its vulnerabilities. Use cases abound, particularly in digital signatures and verification processes where speed remains a priority. Many legacy systems still rely heavily on SHA-1 for their operations, leading to a gradual phase-out rather than an abrupt cessation. The complexities of migration paths and compatibility issues necessitate prolonged usage, compelling security experts to operate with caution, encouraging the gradual erasure of SHA-1 from modern applications.
In summary, while SHA-1 experiences a transitional phase marked by its vulnerabilities, the mechanisms that underpin its function are worthy of admiration. Its mathematical foundation and iterative processes offer insights into the complexities of cryptographic principles. As technology advances and digital threats evolve, understanding SHA-1 enables stakeholders to make informed decisions about the cryptographic measures that secure their data. Thus, one cannot simply dismiss SHA-1 as obsolete; instead, it serves as a reflection of the past, a teacher of lessons learned in the ceaseless pursuit of digital security and integrity.




Leave a Comment