
In the realms of cybersecurity and data protection, hashing and encryption are often conflated, leading to a significant misunderstanding regarding their distinct functionalities. While both techniques serve as methodologies for securing information, they are fundamentally different in both purpose and execution. This exploration aims to elucidate the dissimilarities, thereby fostering a more acute awareness of their unique applications.
To comprehend the differences between hashing and encryption, it is imperative to first delineate their primary objectives. Hashing is a process that transforms input data of arbitrary length into a fixed-size string of characters, which is typically a sequence of numbers and letters. The resulting hash is a unique identifier of the original data set, and vital characteristics of hashing include its deterministic nature—meaning the same input will always yield the same output—and its one-way functionality—implying that it is not meant to be reversed. This characteristic positions hashing at the forefront of data integrity validation.
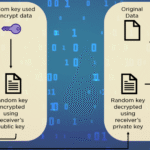
In stark contrast, encryption is concerned with the confidentiality of data. By employing algorithms, encryption transforms readable data (plaintext) into an unreadable format (ciphertext). The primary objective of encryption is to ensure that, even if data falls into the wrong hands, it remains unintelligible without the requisite decryption key. Unlike hashing, encryption is inherently a two-way process; it must permit the recovery of the original plaintext, which underscores its emphasis on data security rather than validation.
The operational mechanisms further accentuate the divergence between these two techniques. Hash functions typically utilize a mathematical algorithm that generates a hash code which is fixed-size and specific to each unique input. For instance, in hashing algorithms like MD5, SHA-1, or SHA-256, even the slightest alteration in the input data—be it a single character or a comprehensive document—results in a vastly different hash outcome. This phenomenon is critical in areas such as digital signatures and data integrity checks, where it is imperative to establish that the data has not been altered during transmission or storage.
On the other hand, encryption employs a range of algorithms, including symmetric and asymmetric cryptography. Symmetric cryptography utilizes a single key for both encryption and decryption, while asymmetric cryptography relies on a pair of keys—a public key and a private key. The complex nature of these algorithms allows for more flexibility in securing sensitive data. For example, even if a malicious actor intercepts encrypted data, without the decryption key, they remain at a loss regarding the information’s original content. This dimension of encryption is pivotal in securing communication channels and protecting transactional data.
However, the inherent differences between hashing and encryption also lead to unique vulnerabilities and risks associated with both methodologies. Hashing, while excellent for integrity verification, is susceptible to certain types of attacks such as collision attacks, where two different inputs produce the same hash output. This vulnerability highlights the importance of utilizing robust and updated hashing algorithms to reduce potential risks.
Similarly, encryption carries its own risks. The storage and management of encryption keys can create vulnerabilities if not handled properly. If a decryption key is exposed or otherwise compromised, the encrypted data becomes easily accessible to adversaries. Moreover, specific encryption standards may become outdated, prompting the necessity for regular updates and enhancements to cryptographic protocols to shield against evolving threats in the cybersecurity landscape.
As technology evolves, the intersection between hashing and encryption continues to expand, often leading to their application in synergy. For instance, it is not uncommon for systems to utilize both hashing and encryption to safeguard sensitive information. Passwords are typically hashed before being stored in databases, ensuring that even if a data breach occurs, the actual passwords remain obscured. Meanwhile, the user’s credentials and communication remain encrypted, thereby further fortifying the security landscape.
An interesting aspect that often garners less attention is the regulatory implications of using hashing and encryption. Various industries, especially those handling sensitive personal information such as finance and healthcare, are governed by standards and regulations that dictate the minimum security practices. Employing hashing for data integrity checks and encryption for data confidentiality can ensure compliance with regulations like GDPR or HIPAA, thus averting hefty penalties associated with data breaches.
Ultimately, the distinction between hashing and encryption is paramount for practitioners and organizations striving for effective data security. Recognizing that these two techniques serve different purposes allows for the formulation of a more comprehensive and robust cybersecurity strategy. Hashing offers integrity verification, signaling whether the information remains unchanged, while encryption safeguards confidentiality, ensuring that unauthorized parties cannot access sensitive data.
This nuanced understanding transcends mere academic discourse; it has profound implications for how information is handled, secured, and shared in our increasingly digital world. Failure to differentiate between these two concepts may lead to misguided security practices, ultimately jeopardizing data integrity and confidentiality. A meticulous approach that embraces the unique strengths of both hashing and encryption can pave the way for a more secure digital future, fostering trust and resilience in our technological frameworks.





Leave a Comment