Have you ever pondered what secrets lie hidden within the digital realms, where vast streams of data flow with capricious abandon? In the world of cryptography, one-way hash functions emerge as stalwart sentinels, ensuring the sanctity and integrity of information. But how does a one-way hash function truly operate? Join us as we delve into the intricacies of these mathematical marvels, exploring their mechanisms, applications, and the challenges they pose in the grand tapestry of cybersecurity.
To embark on this intellectual journey, we must first define what a one-way hash function is. At its core, a one-way hash function is a computational algorithm that takes an input (or message) and produces a fixed-size string of characters, which is typically a digest that uniquely represents the input data. This transformation is characterized by its irreversibility; that is, it is computationally infeasible to reconstruct the original input from the hash output. This property alone poses an intriguing conundrum: if the function is indeed one-way, how do we ever retrieve the original data?
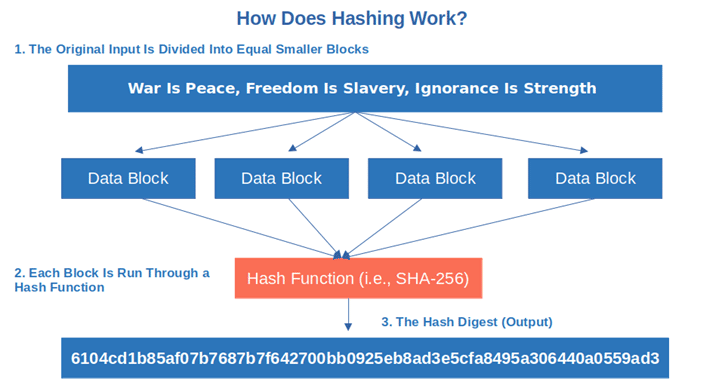
The mechanics behind a one-way hash function can be dissected into several salient features: determinism, fixed output size, efficiency, pre-image resistance, small changes leading to significant output differences, and collision resistance. Each of these components plays a pivotal role in the efficacy of the function.
Determinism signifies that the same input will always yield the same hash output. Imagine a chef meticulously following a recipe; if the ingredients and the preparation steps are consistent, the resulting dish will be identical each time. This reliability is crucial in data verification processes, where verifying that an input corresponds to a given hash can be essential for data integrity.
Equally important is the fixed output size. Regardless of the input’s length, a one-way hash function generates a hash code of a predetermined length. This is akin to a painter selecting a specific canvas size—no matter how lavish the brushwork, the final artwork will occupy the same spatial dimensions. This characteristic ensures uniformity in storage and comparison of hashes, facilitating efficient database operations.
The efficiency of hashing algorithms cannot be overlooked. A high-performing hash function processes inputs at lightning speed, allowing large volumes of data to be processed swiftly. However, this efficiency must be balanced with security; hacking necessitates nefarious means to reverse-engineer the hash function. Hence, it is necessary to construct the algorithm in a manner that complicates these attempts.
Pre-image resistance, a hallmark of one-way functions, means that given a hash output, it is computationally demanding to determine the corresponding input. Consider a labyrinthine puzzle; while it may be possible to walk through the maze and reach the exit, retracing one’s steps is fraught with challenges. This complexity is essential for safeguarding sensitive information, making unauthorized access prohibitively difficult.
A vital aspect of hash functions is the delicate balance between minor input variations and their profound impact on the hash output. A minuscule change—a mere alteration of a single character—can result in a hash that appears utterly distinct from its predecessor. This property is reminiscent of chaos theory, where small changes can lead to vastly different outcomes. This feature is another layer of defense, further obscuring any potential linkage to the original data.
Collision resistance is the final critical trait. It ensures that two different inputs will not yield the same hash output. In essence, it is a safeguard against what could be termed as “hash collisions.” Envision a situation where two individuals are mistakenly assigned the same identification number; such a scenario could precipitate chaos in identification systems. Thus, the consistency of unique hash outputs is paramount for maintaining data accuracy and trustworthiness.
Nevertheless, as with any technology, one-way hash functions are not immune to vulnerabilities. The rapid advancement of computational power has given rise to sophisticated methods aimed at breaking these cryptographic barriers. Techniques such as brute-force attacks, where an adversary systematically attempts all possible inputs, and the emergence of quantum computing present unprecedented challenges to longstanding hashing algorithms. Security researchers have devised avenues to fortify hash functions against these threats, one of which involves transitioning to newer, more robust algorithms that withstand contemporary computational prowess.
As we navigate this perplexing landscape, one must consider a playful challenge: if we cannot retrieve the original message from a hash, how can we establish trust in the integrity of data? This question reveals the fundamental complexity of reliance on hashing in security protocols. Various systems, from secure password storage to digital signatures, hinge upon the efficacy of one-way hash functions. As such, the delicate interplay between convenience, trust, and security calls for perpetual vigilance and robust solutions in cryptographic practice.
In conclusion, one-way hash functions stand as critical guardians of our digital information. Their unique properties facilitate secure and efficient data representation, while their inherent challenges compel ongoing innovation. As we continue to unravel the implications of these powerful algorithms, one can only wonder: in a world where trust is paramount, how will we continue to evolve to maintain the sanctity of our digital existence?






Leave a Comment